En teoría de la probabilidad y estadística, la distribución de probabilidad de una variable aleatoria es una función que asigna a cada suceso definido sobre la variable aleatoria la probabilidad de que dicho suceso ocurra. La distribución de probabilidad está definida sobre el conjunto de todos los eventos rango de valores de la variable aleatoria.
Cuando la variable aleatoria toma valores en el conjunto de los números reales, la distribución de probabilidad está completamente especificada por la función de distribución, cuyo valor en cada real x es la probabilidad de que la variable aleatoria sea menor o igual que x.
Las distribuciones de probabilidad pueden representarse a través de una tabla, una gráfica o una fórmula, en cuyo caso tal regla de correspondencia se le denomina función de probabilidad.
En el siguiente link se definen las distribuciones de probabilidad para variables discretas, distribucion binomial, las distribuciones de probabilidad para variables continuas y la distribucion normal.
http://www.uaq.mx/matematicas/estadisticas/xu4-5.html#t7
El siguiente link nos llevara a una pagina en donde se se muestran las diferentes distribuciones, en la parte inferior de la pagina se encuentran las imagenes de las curvas de probabilidad, dandole click a la imagen nos lelvara a otra pagina donde se explica a detalle cada distribucion. De la misma forma agrege otro link qe nos muestra las tablas de los numeros criticos para cada distribucion.
http://www.itl.nist.gov/div898/handbook/eda/section3/eda366.htm
http://www.itl.nist.gov/div898/handbook/eda/section3/eda367.htm
***** * ***** * ***** * ***** * ***** * ***** * ***** * ***** * ***** * *****
Se denomina Generador de números aleatorios a un algoritmo capaz de producir una secuencia de  números
números  extraídos de una población uniforme mediante sucesos independientes.
extraídos de una población uniforme mediante sucesos independientes.
Notas:
1. | No es una actividad trivial construir este tipo de algoritmos |
2. | Por esta razón en simulación y otras disciplinas se construyen los generadores de números cuasi-aleatorios |
3. | Un generador de números cuasi-aleatorios es aquel en el cual los números obtenidos, aunque no son propiamente aleatorios en un sentido general, son estadísticamente uniformes el intervalo [0,1] y estadísticamente independientes. |
MÉTODOS PARA GENERAR NÚMEROS ALEATORIOS
Básicamente existen dos formas para determinar o generar un número aleatorio usando computadores. Las técnicas más usuales se describen a continuación.
** Dispositivos aleatorios
Son aquellos Generadores, basados en el estado del sistema, en los cuales el algoritmo mide el nivel de alguna variable estocástica del sistema de cómputo, justo en el momento de ser invocado. Por ejemplo, el nivel de voltaje de un circuito integrado del sistema.
Aunque a primera vista es un buen generador, presenta el inconveniente de no poder asegurar que la distribución de probabilidad de la cual provienen los datos sea uniforme.
** Bases de datos
Ello supone producir la secuencia. Un conjunto de números aleatorios, con algún procedimiento externo a la máquina, luego de lo cual la secuencia determinada será la fuente de alimentación de una base de datos.
Con este procedimiento, se logran números que provienen de una distribución uniforme y, además, a través de sucesos independientes; sin embargo, presentan un inconveniente a la vista del ingeniero: consumen recursos valiosos en el computador
** Ecuaciones en diferencias y pseudoaleatoriedadLas ecuaciones en diferencias se emplean para construir generadores de números cuasi-aleatorios . Es decir que tales números no son verdaderamente aleatorios. La razón es que el  número obtenido depende funcionalmente de algunos o todos sus predecesores
número obtenido depende funcionalmente de algunos o todos sus predecesores
Sea  y
y  una secuencia de números (usualmente enteros) indexada bajo la variable independiente
una secuencia de números (usualmente enteros) indexada bajo la variable independiente ![]() y gobernada por la expresión
y gobernada por la expresión  es una ecuación en diferencias (no necesariamente lineal ni homogénea) que quedará totalmente especificada si se determinan las condiciones de frontera
es una ecuación en diferencias (no necesariamente lineal ni homogénea) que quedará totalmente especificada si se determinan las condiciones de frontera  , denominadas semillas del generador entonces el número aleatorio se obtiene mediante una transformación definida por:
, denominadas semillas del generador entonces el número aleatorio se obtiene mediante una transformación definida por:
![]()
Esta transformación asegura que los números ![]() pertenezcan al intervalo
pertenezcan al intervalo ![]() .
.
Notas:
1. | Este es el camino más utilizado actualmente |
2. | La función |
3. | No para cualquier par función-transformación se obtendrán buenos números cuasi-aleatorios. El trabajo para encontrar las apropiadas es, la mayoría de la veces, un trabajo complicado. |
Se encuentran varios tipos de programas basados en ecuaciones en diferencias que vale la pena destacar. El interés de estudio para esos programas, denominados Generadores Clásicos o también conocidos como Procedimientos aritméticos , no va más allá de la simple curiosidad.
*** Un generador no linealLa definición de generador con base en una ecuación en diferencias no restringe la función que se debe emplear; sin embargo, los estudios en el área parecen mostrar que no se requiere procedimientos complejos para obtener números aleatorios, por el contrario la sencillez es una buena tendencia en su diseño.
***** * ***** * ***** * ***** * ***** * ***** * ***** * ***** * ***** * *****
Prueba de Kolmogórov-Smirnov
En estadística, la prueba de Kolmogórov-Smirnov (también prueba K-S) es una prueba no paramétrica que se utiliza para determinar la bondad de ajuste de dos distribuciones de probabilidad entre sí.
En el caso de que queramos verificar la normalidad de una distribución, la prueba de Lilliefors conlleva algunas mejoras con respecto a la de Kolmogórov-Smirnov; y, en general, las pruebas Shapiro-Wilk o Anderson-Darling son alternativas más potentes.
Conviene tener en cuenta que la prueba Kolmogórov-Smirnov es más sensible a los valores cercanos a la mediana que a los extremos de la distribución. La prueba de Anderson-Darling proporciona igual sensibilidad con valores extremos.
Estadístico
La distribución de los datos Fn para n observaciones yi se define como

Para dos colas el estadístico viene dado por

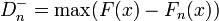
donde F(x) es la distribución presentada como hipótesis.
Prueba de Anderson-DarlingEn estadística, la prueba de Anderson-Darling es una prueba no paramétrica sobre si los datos de una muestra provienen de una distribución específica. La fórmula para el estadístico A determina si los datos <\dots
donde
![S=\sum_{k=1}^N \frac{2k-1}{N}\left[\ln F(Y_k) + \ln\left(1-F(Y_{N+1-k})\right)\right]](http://upload.wikimedia.org/math/a/6/7/a6773e82208231b32ad6852b81a9f782.png)
***** * ***** * ***** * ***** * ***** * ***** * ***** * ***** * ***** * *****
La principal aplicación de la distribución normal en la electrónica está en el campo de las comunicaciones, especialmente en el ruido blanco. El ruido blanco es una interferencia que se presenta en todo rango de frecuencia y afecta todos los sistemas de comunicación; este ruido se comporta como una variable aleatoria normal, con media m = 0. Esta deducción proviene de la transformada de Fourier al espectro de frecuencia de una señal en el tiempo. La obtención de s (desviación standard) depende del ancho de banda, de la frecuencia donde se trabaje y del tipo de señal (voz, radio, tv, etc).

No hay comentarios:
Publicar un comentario